От базы данных к автоматизированной информационно-расчетной системе «Высокочистые вещества и материалы»
Константин Константинович Малышев, Ольга Петровна Лазукина, Елена Нагимовна Волкова
Создание базы данных по высокочистым веществам было начато в 70-х годах прошлого века для информационной поддержки работы Постоянно-действующей Выставки-коллекции веществ особой чистоты и эмирического анализа её данных. Выставка была создана в 1974 году, в период интенсивного развития работ в области получения, анализа, исследования и применения высокочистых веществ и формирования химии высокочистых веществ как науки. Исследовательская программа Выставки включает:
- сбор образцов высокочистых веществ;
- полное и достоверное исследование содержания конкретных примесей;
- составление реальной картины о степени чистоты веществ и тенденций ее изменения во времени;
- поиск закономерностей формирования примесного состава.
К концу 70-х годов база данных по примесному составу высокочистых веществ насчитывала более 6000 элементоопределений и продолжала расти. Появились работы [1-4], где впервые было сформировано представление о возможности рассмотрения содержания примеси, как случайной величины, которая может иметь устойчивые статистические распределения.
Первая версия банка данных по высокочистым веществам была создана в 1982 году [5]. Она включала информацию о образцах Выставки, их свойствах, примесном составе. В основе программного обеспечения был положен пакет прикладных программ АСПИД-3. Первоочередными задачами этой версии было: установление вида функции распределения величины содержания примесей по концентрации, сравнение с теоретически полученным распределением, получение количественных критериев сходности теоретических и экспериментальных данных. Базируясь на вероятностном подходе к закономерностям формирования примесного состава высокочистых веществ, было показано, что функция распределения величины логарифма содержания примесей в высокочистом веществе близка к нормальной.
В процессе развития система переводилась на различные программные и аппаратные платформы, рос объем данных, расширялись список веществ и разнообразие их характеристик. В 1987 г. создается второй вариант банка данных - эта версия была разработана в операционной системе MS-DOS . В 1998 году была выпущена версия, сочетающая в себе функции хранения и обработки данных - информационно-расчетная система (ИРС) «Высокочистые вещества и материалы» [6]. ИРС состоит из баз данных по примесному составу высокочистых веществ (более 50000 элементоопределений), их свойствам, методам получения, метрологическим характеристикам наиболее чувствительных методов их анализа, а также производителям высокочистых веществ, характеристикам их продукции, нормативно-технической документации и пр. Разработаны метода и с использованием ИРС выявлены наиболее общие закономерности в примесном составе высокочистых материалов. Разработан аппарат функций распределения примесей по концентрации, позволяющий рассчитать величины интегральных характеристик (среднее значение концентрации и суммарное содержание всех или определенной группы примесей в образце или выделенной группе образцов) по экспериментальным данным о концентрации ограниченного числа примесей и пределов обнаружения. С развитием ИРС появились задачи, связанные не только с накоплением и обработкой данных, но и с эволюцией самой ИРС. Например, найденные с использованием ИРС закономерности в структуре данных позволили делать оценку входной информации по содержанию конкретных примесей (разработана оригинальная методика, позволяющая оценить полноту и правильность получаемых аналитических данных).
Стремительное развитие информационных технологий, появление новых задач, необходимость расширения структуры данных явились причиной разработки новой версии информационно-расчетной системы.
Архитектура системы
Новая версия информационной базы ИPC построена по объектному принципу с использованием СУБД MS SQL Server 2000. В отличие от прежней, основанной на заранее заданных структурах, ее архитектура предусматривает возможность расширения состава и типов хранимых данных. Структурная схема представлена на рис.1, в ее основе лежит понятие объекта. Объектный подход был выбран для обеспечения возможности вносить изменения в существующие конфигурации данных и добавления новых. В классических решениях для этого приходилось перерабатывать программный код, при этом трудоемкость работы возрастала по мере расширения охвата предметной области. В настоящей версии модификация структуры данных возможна без изменения программного кода. На практике это означает возможность быстрой интеграции в систему новых типов различного рода экспериментальных данных, связанных с измерениями значений свойств веществ и материалов, описаний методик измерения, различного рода справочников и.т.д. Кроме того, можно добавить новые атрибуты в уже созданные структуры.
В наиболее общей и классической постановке [7] объектно-ориентированный подход базируется на концепциях:
- объекта и идентификатора объекта;
- атрибутов и методов;
- классов;
- иерархии и наследования классов.
Любая предметная область описывается набором свойственных ей сущностей. Сущность отображает информационное содержание понятия предметной области. В терминологии объектно-ориентированных систем сущности называются объектами. В рассматриваемой области высокочистых веществ объектами будут «вещество», «свойство», «метод анализа», «примесь», «примесный состав» и т.д. Реализация объекта называется экземпляром. Так, конкретное вещество (например, кремний) есть экземпляр объекта «вещество». Объектно-ориентированные системы оперируют объектами предметной области и их экземплярами. Объект при своем создании получает генерируемый системой уникальный идентификатор, который связан с ним во все время его существования и не меняется при изменении состояния объекта.
Каждый объект определяется его состоянием и поведением. Состояние объекта - набор значений его атрибутов. Поведение объекта - набор методов (программный код), оперирующих над состоянием объекта. Значение атрибута объекта - это тоже некоторый объект или множество объектов. Состояние и поведение объекта инкапсулированы в объекте; взаимодействие менаду объектами производится на основе передачи сообщений и выполнении соответствующих методов.
Множество объектов с одним и тем же набором атрибутов и методов образует класс объектов. Объект принадлежит только одному классу (если не учитывать возможности наследования). Атрибут - это некоторая характеристика объекта, значения которой может быть выражено числом, строкой, логическим значением, изображением, текстом, а также другим объектом. Например, среди атрибутов объекта «образец» можно выделить вещество, степень чистоты, массу, условия хранения и.т.д. Из перечисленных атрибутов «масса» выражается числом, а «Вещество» в свою очередь является объектом со своими атрибутами - формула, наименование, молекулярный вес и т.д.
Допускается порождение нового класса на основе уже существующего класса - наследование. В этом случае новый класс, называемый подклассом существующего класса (суперкласса), наследует все атрибуты и методы суперкласса. В подклассе, кроме того, могут быть определены дополнительные атрибуты и методы. Различаются случаи простого и множественного наследования. В первом случае подкласс может определяться только на основе одного суперкласса, во втором случае суперклассов может быть несколько. Если в языке или системе поддерживается простое наследование классов, набор классов образует древовидную иерархию. При поддержании множественного наследования классы связаны в ориентированный граф с корнем, называемый решеткой классов. В предлагаемой системе используется только простое наследование.
Модель данных разделена на три уровня:
- уровень объектов;
- уровень словаря данных;
- уровень данных.
Уровень объектов хранит описание сущностей. Каждая сущность получает уникальный код, по которому распознается системой. Объектный уровень организован по иерархическому принципу (рис 2).
В вершине находится стандартный объект, который содержит всего один атрибут - наименование. Все остальные объекты наследуются от него. Конкретная реализация данных зависит от предметной области. Так в высокочистых веществах, корневой сущностью служит понятие «вещество», т.к. входит практически во все понятия данной предметной области. Этот объект в иерархии классов является производным от абстрактного стандартного объекта и получает от него единственный атрибут - название.
Каждый объект описывается набором атрибутов (свойств). Атрибуты делятся на три класса:
- простые: числовые, текстовые, логические, дата/время;
- списки;
- ссылки на объекты.
Простые атрибуты хранят первичные значения свойств объекта. Так, для сущности «вещество» простым атрибутом является химическая формула. Список содержит набор возможных значений, из которого выбирается значение свойства. Например, это может быть агрегатное состояние вещества (твердое, жидкое, газообразное, и т.д). Как отмечалось выше, атрибут может представлять собой объект. В этом случае его значением будет ссылка на этот объект. Система использует такую ссылку для доступа к значениям его свойств. Так, понятие «образец высокочистого вещества» содержит в себе понятие «вещество», которое представляет собой атрибут типа «ссылка». На уровне объектов возможны следующие операции:
- добавление нового объекта;
- изменение свойств существующего объекта (добавление, изменение или удаление атрибутов);
- удаление объекта.
Словарь данных содержит значения атрибутов созданных объектов. Его структура представлена на рис. 3. Значение атрибута хранится вместе с идентификаторами значения в зависимости от его типа в соответствующих таблицах, имеющих схожий формат:
- идентификатор значения;
- идентификатор объекта;
- идентификатор атрибута;
- значение атрибута (в зависимости от его типа).
Словарь данных является хранилищем значений атрибутов объектов, и заполняется после определения структуры данных. Для этого предназначен стандартный интерфейс, с помощью которого возможен ввод новых записей, редактирование и удаление имеющихся записей. Данные из словаря копируются в базу данных с помощью специальных процедур, выполняемых на стороне сервера. Они объединены в пакет «генератора таблиц». Непосредственное изменение записей в базе данных не допускается. Все изменения происходят в словаре данных и переносятся в базу в соответствии с правилами и структурой объектной модели данных. Сама структура таблиц базы данных может изменяться, если пользователь вносит новые элементы в структуру первичных данных (рис. 1). Главное назначение базы данных - поставка информации для выполнения запросов. Результаты запросов в виде таблиц могут быть использованы в подключаемых модулях системы или во внешних программах для обработки и расчетов.
Модель данных ИРС «Высокочистые вещества» и прикладные задачи
Модель данных ИРС описывает предметную область «высокочистые вещества и материалы» с акцентом на примесный состав образцов Выставки-коллекции. Ее схема показана на рис.4.
Объектами (классами) верхнего уровня являются: вещество, свойство, получение, анализ, источник. Кроме того, здесь же содержатся общие справочники системы - единицы измерения, классификаторы веществ, города, страны, виды и формы образцов. Класс «вещество» характеризуется следующими свойствами: название, химическая формула, состояние. Таблица Менделеева является производным от вещества и, в дополнение к его атрибутам, имеет только присущие ей свойства, такие, как: порядковый номер, группа, период. Свойства, в свою очередь, разделяются на индивидуальные и примесночувствительные. Общий справочник свойств содержит наименование свойства, единицу измерения, тип. Значения свойств наследуется от объекта «свойство» с добавлением необходимых атрибутов: вещество, значение свойства, источник. Класс «получение» является базовым классом для элементов системы, касающихся методик получения и их характеристик: видов равновесий, коэффициентов разделения. Аналогично построен объект «анализ», который содержит справочник-классификатор методов анализа, справочник методик анализа, данные по пределам обнаружения. Одним из важных элементов системы является объект «источник», который содержит данные о различных типах источников информации. В настоящее время поддерживаются следующие справочники: организации (как источник информации об образце), каталоги фирм, ГОСТы и литературные источники. Все они унаследованы от базового понятия «источник» и дополнены присущими данному типу источника атрибутами.
Данные об образцах высокочистых веществ относятся к основному содержанию системы. Естественно, что атрибуты, свойственные понятию «образец», унаследованы от предыдущей версии, но в данной версии эта структура не является застывшей, а может при необходимости видоизменяться. Базовый класс «образец» включает в себя описанные выше объекты: вещество, анализ, получение, источник.
Естественной классификацией образцов является классификация по типу источника информации о нем:
- организации-изготовители (образцы Выставки-коллекции);
- каталоги фирм (информация о свойствах и примесном составе веществ, получаемых промышленными фирмами);
- ГОСТы - информация о стандартах на высокочистые вещества и материалы;
- литературные источники, в которых представлены данные по получению, свойствам и анализу высокочистых веществ).
Независимо от источника, можно выделить общие свойства класса «образец»:
- вещество;
- источник;
- назначение (лабораторный, промышленный, для микроэлектроники, и.т.д.);
- марка;
- форма образца (монокристалл, поликристалл, жидкость и.т.д.);
- степень чистоты (содержание основного вещества).
- анализ - информация о методиках анализа образца (наименование методики анализа, единица измерения, источник информации, дата проведения анализа)
- данные о результатах анализа образца, полученные с помощью методик, перечисленных в пункте «Анализ» (примесь, содержание).
Остальные атрибуты зависят от источника информации об образце:
- образец Выставки: дата получения, условия хранения, масса, признак «лучший образец», признак «аттестован выставкой»;
- образец из каталога фирм: масса, цена, страница каталога.
Отметим, что приведенная схема может в дальнейшем дополняться как в плане детализации уже имеющихся классов, так и в плане добавления новых структурных элементов в базу данных. Например, уже в ближайшее время в связи с развитием программы по созданию стандартных образцов потребуется выделить понятие «стандартный образец» в отдельную структуру, поскольку для стандартных образцов актуальны данные по нижней и верхней границе определяемых содержаний (доверительные интервалы), которые наравне с измеренным значений концентрации вносятся в паспорт образца.
На прикладном уровне в системе реализованы:
- Интерфейс построения запросов. Пользователь выбирает нужные ему элементы данных, определяет правила и условия отбора данных. В дальнейшем результаты запросов могут быть использованы внешними модулями обработки.
- Модуль обработки данных по примесному составу, в котором используется методика оценки интегральных характеристик - области концентраций, содержащей основную часть примесей и суммарной концентрации по данным анализа, включающим как измеренные значения, так и пределы обнаружения [8]. Встроена возможность экспорта данных в MS Excel. Дальнейшее развитие системы в значительной степени связано с разработкой подключаемых модулей для выполнения различных задач по обработке данных, сопоставления результатов, выявление различного рода закономерностей.
Заключение
Разработанная система, в отличие от предыдущих версий, позволяет пользователю работать со схемой данных, изменять и дополнять ее по мере необходимости. Это означает, что появление новых понятий и сущностей в предметной области «высокочистые вещества и материалы», будет своевременно отражаться в базе данных. При этом не потребуется переработки программного кода, что было неизбежно ранее в таких случаях. В базу включены интерактивные средства для отбора нужной пользователю информации, а так же инструменты для расширения системы за счет подключаемых модулей. Теперь при появлении новых задач соответствующие алгоритмы могут быть встроены в систему, образуя единую библиотеку алгоритмов.
Изображения
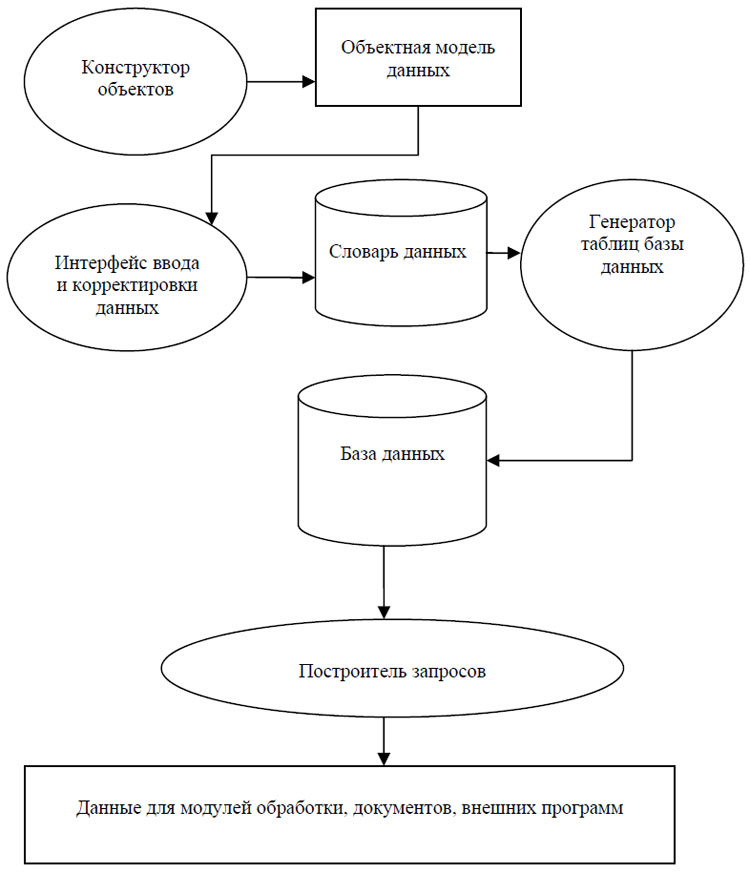
Рис. 1. Структурная схема системы

Рис. 2. Иерархическая модель объектов
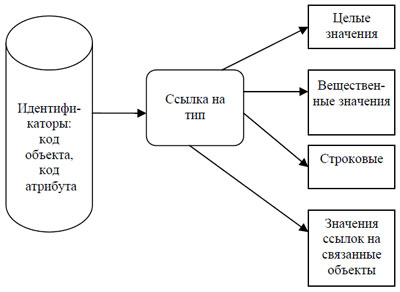
Рис. 3. Блок-схема организации словаря данных
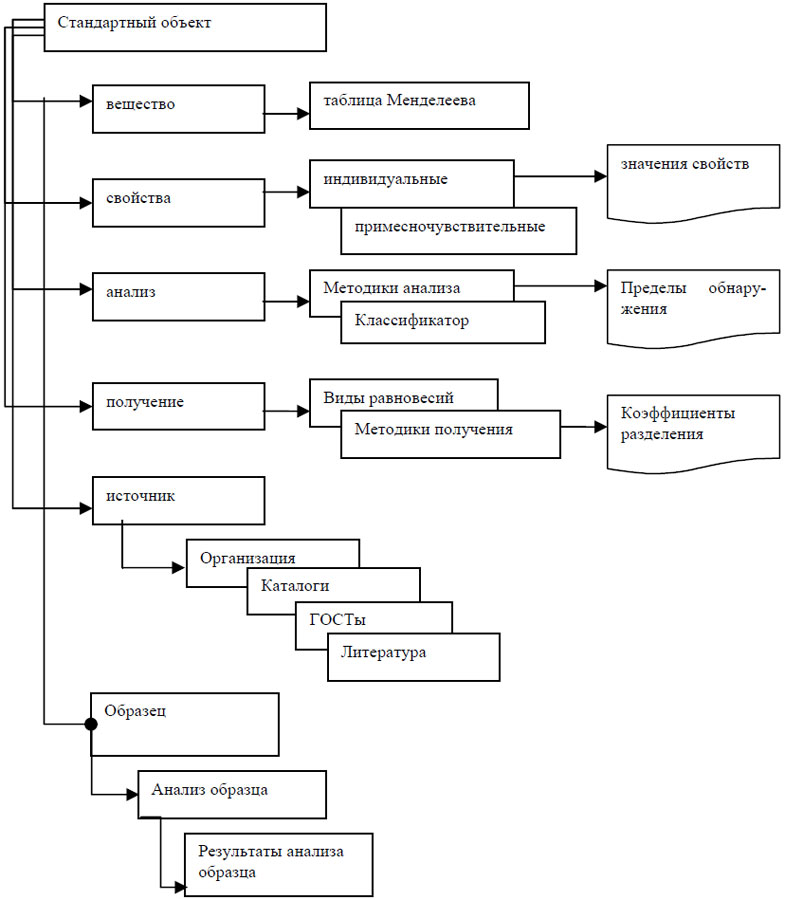
Рис. 4. Схема базы данных ИРС
Список литературы
- Нисельсон Л.А. // В кн.: Получение и анализ веществ особой чистоты. М., Наука, 1966,с.33.
- Сахаров В.М., Алымова Т.Е., Лулова Н.И., Оглоблина И.П.// Получение и анализ веществ особой чистоты: Межвуз. сб. Горьк. гос. ун-т.1974. с. 92
- Девятых Г.Г., Чурбанов М.Ф. //Известия СО АН СССР. Сер. хим. наук. 1978. № 9.вып. 4. с.З
- Девятых Г.Г., Степанов В.М., Чурбанов М.Ф., Крылов В.А., Яньков С.В. // Докл. АН СССР. 1980. т. 254. № 3. с. 670
- Г.Г. Девятых / О создании банка данных по высокочистым веществам. // Вестник АН СССР, 1982, вып. 7, с.35-31.
- Г.Г. Девятых, И.Д. Ковалев, В.А. Крылов, К.К. Малышев, Л.И. Осипова / Информационно-расчетная система «Высокочистые вещества и материалы».// Известия вузов. Материалы электронной техники, 1998, № 3, с.44-51.
- Won Kim. Object-Oriented Databases: Definition and Research Directions // IEEE Trans. Data and Knowledge Eng. 1990. V.2. N3. P.327-341.
- Г.Г. Девятых, И.Д. Ковалев, К.К. Малышев и др. /Анализ данных по примесному составу простых твердых веществ Выставки-коллекции веществ особой чистоты // Высокочистые вещества. 1992. №5-6. С.7-11.
Об авторе: Институт химии высокочистых веществ им. Г.Г. Девятых РАН
Нижний Новгород, Россия
ехро@ihps.nnov.ru
Материалы международной конференции Sorucom 2014 (13-17 октября 2014)
Помещена в музей с разрешения авторов
2 июля 2015