Производительность СУБД
Среди многих факторов, влияющих на производительность СУБД, выберем два, имеющие прямое отношение к параллельным вычислительным платформам сегодняшнего дня:
- поддержка параллелизма;
- реализация многопотоковой архитектуры.
Параллельные алгоритмы
Одним из способов достижения более высокой производительности является использование алгоритмов распараллеливания заданий. В СУБД существует три области применения таких алгоритмов:
- параллельный ввод/вывод,
- параллельные средства и утилиты администрирования,
- параллельная обработка запросов к базе данных.
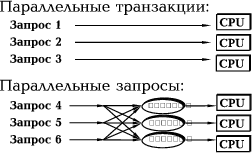
Рис. 4. Распараллеливание ввода/вывода
Распараллеливание ввода/вывода (рис. 4) в сочетании с оптимальным планированием заданий позволяет осуществить весьма эффективный одновременный доступ к фрагментированным таблицам и индексам, расположенным на нескольких физическим дисках, тем самым многократно ускоряя операции с относительно медленными внешними устройствами. Выполнение административных утилит (в том числе реорганизация данных, сортировка, построение индексов, загрузка и выгрузка данных, архивирование и восстановление баз данных) также должно быть полностью параллельным, включая распараллеливание операций ввода/вывода, хотя на практике это требует доработки лишь небольшого числа механизмов.
В отличие от параллельных ввода/вывода и администрирования, параллелизм в обработке запросов реализуется гораздо сложнее. Теоретическим обоснованием возможности распараллеливания запросов в реляционной СУБД является свойство реляционной замкнутости - результатом каждого реляционного оператора: SELECT - выборка подмножества строк отношения (таблицы); PROJECT - выборка подмножества полей (столбцов); JOIN - соединение двух таблиц, является новое отношение, а поскольку любой запрос можно разбить на иерархию элементарных операторов, то разумно попытаться выполнить их параллельно. Языку запросов SQL, несомненно, внутренне присущ параллелизм. Обработка запроса обычно состоит из множества атомарных операций, состав и последовательность которых, т.е. план запроса (рис. 5), определяется оптимизатором после просмотра нескольких вариантов. В недалеком прошлом все эти операции выполнялись в строгой последовательности, результат каждой служил исходным набором данных для последующей. Параллелизм в обработке запросов подобен идее "разделяй и властвуй" или коллективному выполнению задания. Вследствие разделения задания на части между несколькими работниками результат достигается быстрее. Для обеспечения параллелизма в сервере баз данных производитель должен выбрать такой набор атомарных операций, например, scan - просмотр таблицы, sort - сортировка, join - соединение двух таблиц, которые (а) могли бы тиражироваться и выполнять свою часть задачи одновременно, и (б) результаты их работы можно было бы объединить, как если бы задача была выполнена одним исполнителем.
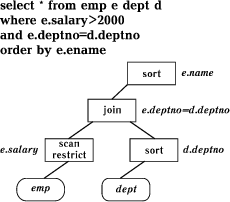
Рис. 5. Порядок выполнения SQL-запроса.
Для обеспечения параллелизма в сервере СУБД требуется, чтобы декомпозиция и параллельное выполнение запроса были осуществимы независимо от средств межзадачного взаимодействия, принятых в конкретной вычислительной системе. Создание множества тиражируемых копий одной атомарной операции, одновременно выполняющих одну и ту же задачу, можно назвать горизонтальным параллелизмом.
Дополнительная степень параллелизма, иначе - вертикальный параллелизм, может быть достигнута при параллельном запуске нескольких, в общем случае различных атомарных операций, которые обычно должны выполняться последовательно. Здесь применима аналогия с конвейером - все операции, составляющие конвейер, находятся на некоей стадии выполнения и, следовательно, активны в одно и то же время. В случае с базами данных, исполнение каждой атомарной операции начинается сразу же с появлением данных, которые она должна обрабатывать, не дожидаясь завершения предыдущего шага и накопления полученных там данных в промежуточном буфере. Сигналом к запуску последующей операции является момент начала поступления данных для нее. Например, операция соединения таблиц может начинать работать одновременно с операциями последовательного чтения с диска и фильтрации строк, а ее результаты по мере поступления могут быть переданы на вход операции сортировки, например, для начального разделения данных по ключу в соответствии с алгоритмом упорядочивания, и при этом все три вида операций: сканирования, объединения и сортировки, продолжают работать одновременно. Такой подход, во многом сходный с конвейерной обработкой в современных процессорах, носит название "потока данных" (data flow) или "управления по требованию" (demand driven). Дополнительным плюсом этого подхода является то, что его можно успешно применять в аппаратной архитектуре с любой степенью параллелизма, кроме того, внедрение принципа вертикального параллелизма оставляет большое пространство для совершенствования самих алгоритмов, и дает возможность производителям СУБД воспользоваться последними достижениями теории алгоритмов без изменения серверной архитектуры.
Применение вертикального и горизонтального параллелизма (рис. 6) увеличивает общую производительность и сокращает время реакции информационной системы за счет ускорения процедур обработки данных. В свою очередь, рост объемов обрабатываемых данных обеспечивается вертикальным и/или горизонтальным масштабированием аппаратной платформы.
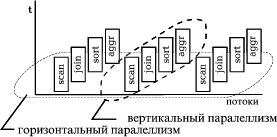
Рис. 6. Горизонтальный и вертикальный параллелизм в обработке SQL-запроса.
Многопотоковая архитектура СУБД
Идея обеспечить распределение вычислительных ресурсов между запросами от многих пользователей непосредственно в сервере СУБД, не доверяя средствам операционной системы, возникла из необходимости обслуживать все большее число пользователей, снизив при этом значительные накладные расходы ОС на сохранение и загрузку контекста их процессов, по сути подобных друг другу. Способ организации одновременной обработки множества запросов внутри сервера баз данных при минимальных накладных расходах на переключение контекста и максимальном разделении вычислительных ресурсов между ними называется истинно многопотоковой (рис. 7) архитектурой (не следует путать с имитацией многопотоковости с помощью дополнительного уровня между клиентами и сервером - диспетчера-мультиплексора запросов, что позволяет серверу обрабатывать запросы лишь последовательно).
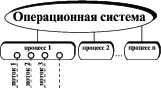
Рис. 7. Иерархия ОС, процессов и потоков.
Поток (thread) - это фрагмент контекста одного процесса, включающий только те данные (стек рабочих переменных и текущего состояния), которые необходимы для реализации выполняемых потоком функций. Поток можно организовать или средствами самого процесса, например, процесса сервера баз данных, или с помощью соответствующих служб современных ОС.
Часто в качестве синонима потока используется термин "легковесный процесс" (light-weighted process), поскольку затраты ресурсов на запуск, останов, а также создание или уничтожение потока силами управляющего процесса гораздо ниже по сравнению с действиями ОС над обычными процессами. В принципе, для обеспечения параллелизма поток может быть клонирован или поделен на подзадачи - потоки более низкого уровня, примерно так же, как и любой процесс внутри операционной системы. В результате потоки избавляют операционную систему от создания, планирования и манипуляции множеством процессов, и, следовательно, задачи самой ОС существенно меньше загружают вычислительную систему.
Итак, истинно Многопотоковая архитектура обеспечивает более совершенное разделение ресурсов между прикладными задачами и операционной системой, а также более высокий уровень стабильности по мере роста числа пользователей, чем традиционные много процессные архитектуры. Но помимо этого, многопотоковость может повысить независимость между модулями сервера баз данных, поскольку выполнение условных переходов внутри сервера может основываться на событиях, возникающих в результате взаимодействия потоков, а не на прямой реализации кода, что позволяет надеяться на повышение стабильности и безболезненное развитие кода самого сервера.
Выполняя все функции управления ресурсами, необходимыми СУБД, включая динамическое размещение буферов в памяти, выделение пространства на диске, систему блокировок и пр., Многопотоковая архитектура сервера баз данных фактически является специализированной операционной системой, манипулирующей множеством потоков и планирующей их выполнение. По аналогии с подходами в реализации ОС, планировщик многопотоковой СУБД может быть выполнен как вытесняющий или не вытесняющий. В не вытесняющей схеме поток продолжает выполняться до тех пор, пока сам не просигнализирует планировщику о завершении какого-то кванта работы, после чего планировщик назначает на выполнение другой поток. Обычно такой планировщик использует кольцевой (round-robin) алгоритм постановки потоков в очередь на запуск. Выполняемый поток определяет момент своей остановки по истечению временного интервала, выполнению критической секции кода или по необходимости выполнить блокирующий вызов, например, операцию ввода/вывода. Такой механизм удобен для сервера, занимающегося исключительно обслуживанием базы данных, или в среде однотипных запросов, где потоков относительно немного и, следовательно, их поведение хорошо предсказуемо. В вытесняющей схеме поток может быть прерван по инициативе планировщика, например, при попадании в очередь более приоритетного потока. Этот принцип эффективен в системах с неспецифицированными запросами или при параллельной загрузке системы задачами, не связанными с базами данных, т.е. там, где стратегия планирования в зависимости от решаемых задач может изменяться в широких пределах.