Рекурсивные вычислительные системы
Малоизвестные страницы истории развития вычислительной техники
М. Б. Игнатьев, Ю. Е. Шейнин, Санкт-Петербургский государственный университет аэрокосмического приборостроения
Истоки разработки
В феврале 1972 г. на базе кафедры технической кибернетики в Ленинградском институте авиационного приборостроения (ЛИАП) была создана кафедра вычислительных систем и сетей, возглавил которую д. т. н. М. Б. Игнатьев – один из авторов этих строк. С момента своего основания эта кафедра помимо традиционных направлений исследования в области робототехники стала развивать новое направление, связанное с разработкой развивающихся вычислительных систем нетрадиционной архитектуры.
В тот период в Советском Союзе шла борьба между двумя тенденциями дальнейшего развития вычислительной техники. Первая ориентировалась на проведение и совершенствование собственных разработок, таких, как серии машин БЭСМ, "Урал" и др. Вторая нацеливалась на использование зарубежного опыта, прежде всего копирование машин фирмы ИБМ.
Необходимо отметить, что в это время фирма ИБМ занимала практически монопольное положение в сфере производства ЭВМ и их продвижения на рынок, нередко при этом грубо нарушая законы о монополиях и ведя судебные процессы как в США, так и за рубежом. Этот монополизм проявлялся и в компьютерной литературе – там описывались машины ИБМ и почти ничего не говорилось о машинах конкурирующих фирм, например, Контрол Дейта Корпорейшен, Бэрроуз и др. В машинах же фирмы ИБМ реализовывалась классическая неймановская архитектура, которая в целом ряде ситуаций уже не могла удовлетворить потребителей.
В этой ситуации наша молодая кафедра, выделившаяся из кафедры технической кибернетики ЛИАП в феврале 1972 г., решила развивать нетрадиционные многопроцессорные вычислительные системы, которые в перспективе могли обеспечить более высокую производительность и надежность. Для нас такое решение было продолжением работ в области цифровых дифференциальных анализаторов, которые являлись многопроцессорными специализированными рекурсивными структурами с обратными связями, высокопроизводительными и надежными за счет введения избыточности методом избыточных переменных, который ранее был нами разработан [1, 2, 4–9]. Важный шаг был сделан доцентом ЛИАП В. А. Торгашевым, предложившим распространить и развить эти принципы на универсальные вычислительные машины. В итоге и родилась концепция рекурсивных машин, которая получила поддержку Государственного Комитета СССР по науке и технике в Москве и Института кибернетики во главе с академиком В. М. Глушковым в Киеве. Сложился коллектив из москвичей, которых представлял В. А. Мясников, киевлян, руководимых В. М. Глушковым, и ленинградцев с общим центром в ЛИАП.
Наиболее ярко предложенная нами концепция была представлена в докладе на международном конгрессе ИФИП в Стокгольме в 1974 г. [10]. Этот доклад сделал М. Б. Игнатьев; советская делегация отнеслась к докладу очень холодно, зато иностранцы приветствовали доклад, который фактически ниспровергал компьютерные авторитеты и традиционную архитектуру и провозглашал нетрадиционную рекурсивную архитектуру. Так впервые советская компьютерная разработка была анонсирована на международной арене, что привлекло к ней внимание многих. Итогом этой акции явилось, во-первых, включение работы в программу ГКНТ с выделением финансирования на создание экспериментального образца рекурсивной машины; во-вторых, заключение соглашения с фирмой Контрол Дейта о создании образца рекурсивной машины на основе предложенных нами архитектурных решений; в-третьих, предоставление в наше распоряжение самой лучшей для того времени элементной базы и средств отладки. Руководителем рабочей группы по сотрудничеству с фирмой Контрол Дейта Корпорейшен стал М. Б. Игнатьев, который и в дальнейшем в этом качестве развивал проект по рекурсивной машине, и, в частности, занимался покупкой машины Сайбер для Ленинградского научного центра АН СССР.
На базе этой машины фактически организовался сначала Ленинградский научно-исследовательский вычислительный центр, а потом и Ленинградский институт информатики и автоматизации АН СССР.
Следует отметить, это было время некоторого потепления советско-американских отношений, сопровождавшееся и расширением научного сотрудничества, именно в этот период реализовывался, например, проект Союз-Апполон. Таким образом, в результате стечения благоприятных обстоятельств нам удалось развернуть деятельность по реальному созданию рекурсивной машины. Закипела работа, в которой принимали участие многие сотрудники нашей кафедры – В. А. Торгашев, В. И. Шкиртиль, С. В. Горбачев, В. Б. Смирнов, В. М. Кисельников, А. М. Лупал, Ю. Е. Шейнин и многие другие. В результате к началу 1979 г. были изготовлены многие блоки машины, и в том же году экспериментальный образец рекурсивной машины был предъявлен государственной комиссии во главе с академиком А. А. Дородницыным.
В специальном Постановлении ГКНТ СССР и Комиссии Президиума Совета Министров СССР от 14.09.1979 г. за №472/276 отмечалось, что "запуск первого в мире экспериментального образца многопроцессорной рекурсивной машины высокой производительности и надежности является достижением мирового уровня". Были разработаны планы дальнейшего развития этой работы, но в декабре 1979-го советские войска вошли в Афганистан, и правительство США разорвало все научно-технические связи с СССР, в том числе и контакты по линии фирмы Контрол Дейта, что нанесло нам большой ущерб. Но начатая работа продолжалась, хотя к этому времени наш коллектив разделился – часть сотрудников во главе с В. А. Торгашевым в январе 1980 г. перешла в только что образованный Ленинградский научно-исследовательский вычислительный центр АН СССР, другая часть продолжала работать на нашей кафедре над созданием различных модификаций многопроцессорных систем. Отдел рекурсивных машин был создан в Институте кибернетики в Киеве. Таковы внешние контуры этой пионерской работы.
Принципы организации рекурсивных машин и систем
В математике существует большой раздел – рекурсивные функции [3]. Долгое время термин "рекурсия" употреблялся математиками, не будучи чётко определённым. Его приблизительный интуитивный смысл можно описать следующим образом. Значение искомой функции Ф в произвольной точке Х (под точкой подразумевается набор значений аргументов) определяется, вообще говоря, через значения этой же функции в других точках Н, которые в каком-то смысле предшествуют Х. Само слово "рекурсия" означает возвращение [17]. Рекурсивные функции – это вычислимые функции. По сути дела все вычислимые на компьютерах функции – это рекурсивные функции, но разные компьютерные архитектуры по-разному ведут вычислительные процессы. Чем лучше соответствует структура компьютера структуре задач, тем меньше затраты памяти и времени. Так что когда мы говорим о рекурсивных машинах, мы говорим о соответствии структур машины и решаемых задач, а так как задачи бывают разные, то структура машин должна гибко подстраиваться к структурам задач. Математика в настоящее время погружена в программирование, и в программировании рекурсивные операции распространены.
ЭВМ выступает как средство материализации логико-математических преобразований. ЭВМ являет собой иллюстрацию концепции потенциальной осуществимости, поскольку при отсутствии ограничений на время работы и емкость памяти любая ЭВМ в состоянии провести любые вычисления. Конкретное же протекание процессов вычисления проявляется лишь на уровне организации преобразований информации (задействуются конкретные регистры, коммутаторы, процессоры, линии передачи данных в определенном порядке и сочетании и т. д.). С этой точки зрения архитектура ЭВМ – это её структура в состоянии (процессе) реализации алгоритма, т. е. как бы ожившая структура. Философской основой такого представления является теория отражения, раскрывающая отображение категорий и явлений одной природы (числа, алгоритмы) на объекты другой природы (физические элементы, сигналы). Причем это отображение взаимно неоднозначно – алгоритму аj может соответствовать множество архитектур {А} и обратно – архитектуре Аj непосредственно не соответствует какой-либо алгоритм аj. Специфика взаимодействия {а} и {А} раскрывает глубинные свойства диалектического процесса развития математики и вычислительной техники как частного случая взаимодействия абстрактного и конкретного. Как отмечает С. А Яновская, "лицо машинной математики все более зависит от развития философских и логических оснований математики" [23]. Не представляется возможным непротиворечивая формализация отображения {а} -> {А} из-за его неоднозначности. Поэтому построить соответствующую аксиоматическую теорию проектирования ЭВМ не представляется возможным [24].
Когда мы формулировали принципы организации рекурсивных машин, мы исходили из потребностей развития вычислительных машин и систем. Мы получили множество авторских свидетельств [13, 14, 15 и др.], это был интересный творческий процесс и с точки зрения достоверности сделанного тогда, в 1974–1979 гг., стоило бы полностью воспроизвести наш доклад на конгрессе ИФИП в Стокгольме [10]. Он содержал анализ недостатков машин традиционной архитектуры, ревизию принципов фон Неймана, принципы архитектуры рекурсивных машин, основные особенности языка рекурсивных машин, фрагментарное описание рекурсивной машины.
В качестве иллюстрации рекурсивной структуры можно привести систему 3М – модульную микропроцессорную систему [18]. Система 3М строится из модулей трех типов – операционных, коммуникационных и интерфейсных. Операционные модули выполняют основную работу по обработке данных, реализации объектов математической памяти, процессов определения готовности и выполнения операторов программы на внутреннем языке. Коммуникационный модуль предназначен для реализации коммуникационной системы – установления логического соединения между модулями, обмена информацией между модулями, поиска в системе ресурсов запрошенного типа. Интерфейсные модули подключаются к внешним устройствам своими блоками ввода-вывода. Вопросы организации обмена информацией с внешним миром имеют большое значение для существенно многопроцессорных систем, оказывают значительное влияние на их фактические характеристики. Различные классы задач требуют разной интенсивности обмена с внешними устройствами. Вычислительная система должна обеспечивать построение таких ее конфигураций для каждого конкретного применения, которые бы обладали оптимальными для этого применения характеристиками по вводу-выводу. Система 3М обеспечивает инкрементное наращивание вычислительной мощности до любого необходимого значения путем подключения дополнительных блоков без внесения изменений в имеющуюся систему и ее программное обеспечение как на этапе разработки системы, так и в ходе ее эксплуатации. Методология проектирования и реализации системы 3М базируется на рассмотрении вычислительной системы как иерархии виртуальных машин. Система 3М имеет рекурсивно-организованную многоуровневую структуру. Рекурсивность структуры состоит в том, что структура всякой модификации системы задается рекурсивным определением. Динамически меняющиеся в ходе вычислений виртуальные процессы требуют постоянной динамической реконфигурации связей между модулями. В настоящее время реализуются системы, содержащие тысячи и миллионы процессоров.
Экспериментальная реализация параллельных вычислительных систем для динамических параллельных вычислений
Ниже в хронологическом порядке рассматриваются экспериментальные образцы, разработанные начиная с 1974 года.
1979 год
Первой параллельной ВС на микропроцессорных СБИС стал разработанный в 1979 г. экспериментальный четырехпроцессорный образец Рекурсивной ЭВМ (РВМ).
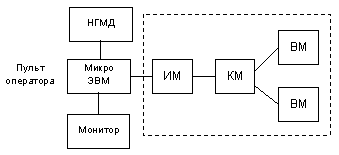
Структура экспериментального образца микропроцессорной РВМ
Экспериментальный образец РВМ включал два вычислительных модуля, один коммуникационный модуль и интерфейсный модуль (процессор ввода-вывода). Его структура представлена на рис. 1. Построенный на секционных микропроцессорах, он показал принципиальную возможность создания модульных параллельных ВС с распределенной архитектурой, с распределенными параллельными вычислениями. Их эффективная поддержка реализовывалась в архитектуре и структуре модулей параллельной ВС – вычислительных модулях, реализовывавших собственно вычисления и новые механизмы децентрализованного управления; в коммуникационных модулях, аппаратно-микропрограммно реализовывавших протоколы коммуникационной системы для взаимодействия параллельных процессов, идущих в вычислительных модулях. Операторы внутреннего языка РВМ – языка высокого уровня, соответствовали среднегранулярным, микропрограммно-реализованным процессам обработки информации. Управляющие операторы внутреннего языка реализовывали основные механизмы управления параллельными вычислениями на уровне сети таких операторов.
1982–1985 гг.

Диплом ГКНТ СССР за разработку высокопроизводительных рекурсивных многопроцессорных комплексов
По результатам испытаний экспериментального образца микропроцессорной ВС были организованы работы по созданию высокопроизводительных параллельных ЭВМ – Рекурсивных ЭВМ. Они проводились в сотрудничестве ИК и ЛИАП с привлечением ряда промышленных организаций. В Институте кибернетики АН УССР создавался образец большого вычислительного комплекса – макроконвейерного вычислительного комплекса для решения больших задач, в ЛИАП (ныне СПбГУАП) – модульная масштабируемая параллельная ВС "Система 3М" на микропроцессорной элементной базе. Было создано два параллельных ВС – большая макроконвейерная ВС класса mainframe для вычислений большой разрядности (64–128 разрядов), с перспективами масштабирования на уровень суперкомпьютерных ВС, – в ИК АН УССР, и в ЛИАП – модульная масштабируемая микропроцессорная ВС "Система 3М", для решения задач с разрядностью 16–32 разряда. Работа было высокого оценена государственной комиссией ГКНТ СССР (рис. 2).
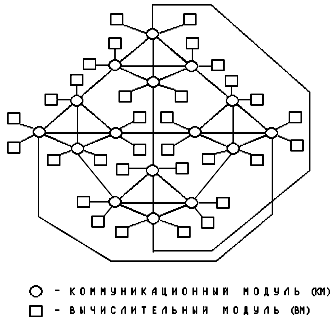
Проект 32-процессорной микропроцессорной параллельной ВС «Система 3М»
В проекте "Системы 3М" большое внимание уделялось модульности и масштабируемости. Общая структура проекта "Системы 3М" приведена на рис. 3, который иллюстрирует топологию этой системы. Структура разработанной параллельной ВС включала 32 вычислительных модуля, 16 коммуникационных модулей. Модульная структура с рекурсивно определяемой топологией связи обеспечивала масштабирование параллельной ВС путем увеличения числа модулей при сохранении как структуры модулей, так и системного и прикладного ПО.
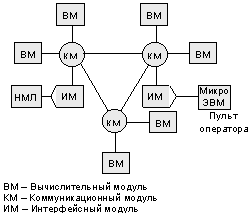
Структура экспериментального образца параллельной ВС «Система 3М»
Поддержка свойства масштабируемости в системных механизмах распределенной ОС и коммуникационных модулей позволяет создавать на типовых узлах ограниченной номенклатуры программно-совместимые параллельные ВС с широким диапазоном характеристик по производительности, объему памяти и пропускной способности ввода-вывода (использовалось три типа модулей – вычислительные модули, коммуникационные модули и интерфейсные модули).

Общий вид экспериментального образца параллельной ВС «Система 3М»
Был создан экспериментальный образец "Системы 3М" (рис. 4, 5), разработано его системное ПО, проведен большой комплекс исследований и экспериментов по решению на нем прикладных задач различного класса.
1986–1988 г.
Развитие микропроцессорной техники, создание все более мощных микропроцессоров и достаточно производительных микропроцессорных узлов на их основе, освоение их серийного производства и применение для широкого круга задач поставили вопрос о создании параллельных ВС на основе серийно выпускаемых микропроцессорных модулей, в том числе для систем специального назначения.
При реализациях параллельных ВС на готовых микропроцессорных узлах (спустя десятилетие этот подход получил название COTS – Commercial Off The Shelf) функциям и свойствам ВМ уровня логической структуры на уровне физической структуры наиболее полно будет соответствовать пара ВМ – терминальный коммуникационный модуль (ТКМ). Комбинация ВМ-ТКМ дает основу для реализации полного набора функций ВМ. ТКМ в таких системах подключается на системную (локальную) шину серийного микропроцессорного узла (Q-bus, VME, PCI) и занимает место коммуникационного контроллера (КК).
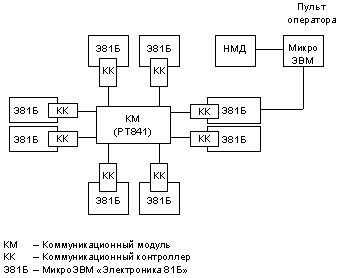
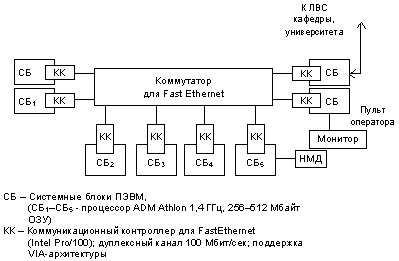
Параллельная ВС на базе серийных микроЭВМ «Электроника 81Б»
Параллельная ВС такого класса была разработана нами на основе серийной микроЭВМ "Электроника 81Б", пригодных и для возимых, и для бортовых применений (рис. 6). На стандартную системную шину (для "Электроники 81Б" – шина Q-bus) в качестве КК подключается специальная относительно несложная плата, реализующая высокоскоростной дуплексный внутрисистемный интерфейс параллельной ВС. Учитывая ограниченный диапазон масштабируемости для разрабатывавшихся параллельных ВС, а также целевые области применения, в данном проекте параллельной ВС (название "РВМС" – Распределенная мультипроцессорная ВС) была принята линия на перенос сложности реализации внутрисистемных протоколов с КК вычислительных модулей на коммуникационные модули. Для РМВС в качестве КМ был разработан специализированный коммуникационный транспьютерный модуль РТ841. Аппаратно-микропрограммная реализация внутрисистемных протоколов нижнего уровня, доступный микропрограммный уровень и специализированные на логическую обработку параллельные блоки при достаточно высокой тактовой частоте позволили сбалансировать характеристики коммуникационной системы на базе такого ТКМ с максимальной пропускной способностью, которую могут обеспечить вычислительные модули на базе "Электроники 81Б", в конфигурациях до 8 вычислительных модулей на один КМ. Большие конфигурации (до 18 ВМ) комплексируются с использованием 3 КМ, объединенных в полносвязанную структуру, где удельная пропускная способность КС (пропускная способность на 1 ВМ) остается в том же диапазоне, что и для базовой мультипроцессорной конфигурации с одним ВМ. Для созданного в ЛИАП экспериментального образца РМВС (конфигурация с 8 ВМ и 1 КМ) была разработана распределенная ОС, система программирования на языке Си, система отладки с распределенным отладочным монитором ("РОМ") [25]. Операционная система РМВС послужила прообразом разработанной в 90-х годах операционной системы НевОС . Опыт создания системы параллельного программирования для РМВС, ее применения для программирования достаточно больших программных комплексов послужили отправной точкой для постановки работ по системам визуального параллельного программирования, создания в последующие годы языка и системы программирования ВИЗА.
1989–1992 гг.
Другая линия развития параллельных ВС, объединяющая разработку специальной структуры ВМ с использованием в качестве его ядра СБИС микропроцессора с фиксированной системой команд, была предложена для отечественных проектов 32-разрядных микропроцессоров новой архитектуры, создававшихся в конце 80-х – начале 90-х годов. В качестве ядра ВМ были рассмотрены (совместно с НПО "Элас", Зеленоград) микропроцессор "Салют" – микропроцессор, разрабатывавшийся для бортовых ВК перспективных космических аппаратов, и микропроцессор "Эль-90" – микропроцессорная реализация архитектуры "Эльбрус" (совместно с Институтом точной механики и вычислительной техники). И в том и в другом микропроцессорном наборе имелись возможности интеграции в структуру ядра ВМ специализированного коммуникационного контроллера и расширения базовой системой команд некоторой формой экстракодов. Структура ВМ на базе МП "Салют" приведена на рис. 7.
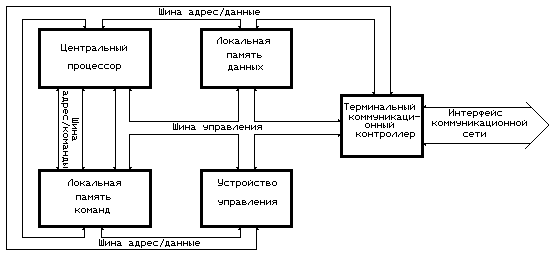
Структура вычислительного модуля на базе микропроцессорного набора «Салют»
Учитывая вариант включения функцией ТКМ в перечень прямо аппаратно-программно реализуемых в ВМ функций (с исключением ТКМ как самостоятельного компонента физической структуры) и в духе транспьютерных технологий можно считать такое "поглощение" ТКМ вычислительным модулем наиболее перспективным вариантом. Это позволило погрузить в архитектуру вычислительных модулей КК для внутрисистемных коммуникаций в параллельной ВС, реализовать алгоритмы КС с высокой эффективностью. Оценки и моделирование свидетельствовали, что достижимые в таких системах показатели задержки доставки сообщений между ВМ (L), накладных расходов ЦП ВМ на передачу сообщения (o), интервал между последовательно передаваемыми сообщениями (g) сбалансированы с характеристиками производительности вычислительного ядра ВМ. Расширение системы команд экстракодами управления процессами позволяло в два-три раза снизить накладные расходы на переключение процессов s, снизить показатель o.
1992–1994 гг.
Развитие в мире транспьютерных технологий определило интерес отечественной промышленности к этому классу ВС и направление ряда наших проектов в области параллельных ВС. Проведенные исследования и эксперименты с транспьютерными модулями на основе транспьютеров Т805 показало преимущества глубокой интеграции механизмов управления процессами, мультипрограммного режима работы транспьютера как компонента параллельной ВС с распределенной архитектурой. В то же время были видны и преимущества наших подходов с инкапсулированием последовательных программ внутри процессов – целостных компонентов параллельной схемы программы, с более высоким уровнем сервиса КС и используемых в ней протоколов, развитых средств сегментации и управления памятью в архитектуре ВМ.
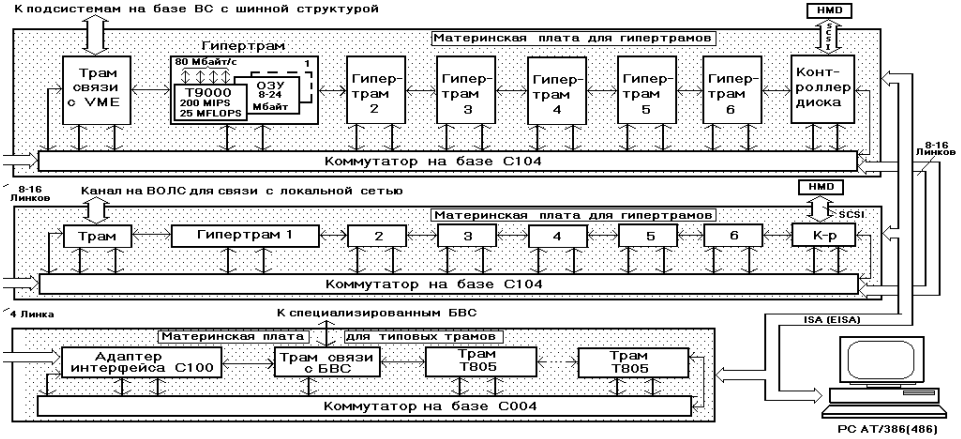
Структура макета транспьютерной БВС на серийных транспьютерных модулях («гиперТРАМАах»)
Выводы наших исследований были подтверждены и практикой развития самих транспьютерных технологий, появлением нового поколения транспьютеров – Т9000. Т9000 развивал транспьютерные архитектуры именно в тех направлениях, которые указывались нами как ограничения семейства Т800, имевшиеся в наших архитектурных и структурных решениях в указанных выше проектах. Хотя и в Т9000 мы не увидели полного набора искомых функциональных возможностей для системной поддержки динамических параллельных вычислений в параллельных ВС с распределенной архитектурой, в целом они давали хорошую основу для построения параллельных ВС. Недостающие механизмы реализовывались на них программно в ядре ОС с приемлемой эффективностью. Нами был разработан проект параллельной ВС на транспьютерах. Структура макета такой параллельной ВС показана на рис. 8.
Кластерная ВС на серийных высокопроизводительных системных блоках и сетевых средствах
Следующим этапом работы стал проект высокопроизводительной кластерной ВС с масштабируемой конфигурацией, реализованный полностью на серийных технических средствах: системных блоках ПЭВМ, серийных сетевых контроллерах и коммутаторах с диапазоном производительности от 10 до 100 Гфлоп при стоимости порядка 0,3 долл. за 1 Мфлоп (300 долл. за 1 Гфлоп, оценки по техническим характеристикам микропроцессоров на июнь 2001 г.). На рис. 9 и 10 представлены структуры 8-и 36-процессорных конфигураций кластерной ВС.
Структура кластерной ВС на серийных системных блоках и сетевых средствах
Разработка параллельных кластерных ВС лежит в русле основных современных тенденций создания высокопроизводительных вычислительных средств (СВТ) широкого применения для решения современных сложных нерегулярных вычислительных задач [26]. С другой стороны, для нас это возврат на новом этапе к созданию параллельных ВС на основе серийно выпускаемых блоков вычислительной техники, который был нами апробирован в параллельной ВС на микроЭВМ "Электроника 81Б".
Однако в отличие от предыдущего проекта на "Электроника 81Б" проект кластерных ВС строился с ориентацией на создание СВТ широкого применения, где кроме показателя абсолютной производительности ВС важное значение имеют технико-экономические характеристики, удельная стоимость достигаемой производительности. Это определяет отличия в подходах к проектированию кластерной ВС, ориентацию на максимальное использование серийных (за счет этого – дешевых) технических средств для реализации физического уровня параллельной ВС. Если в проекте параллельной ВС на микроЭВМ "Электроника 81Б" готовым компонентом были микроЭВМ – основа ВМ параллельной ВС, а средства реализации коммуникационной системы были специальной разработки, то проект кластерной ВС использует готовые, серийно выпускаемые технические средства и в качестве основы построения КС. Средства реализации КС составляют существенную часть затрат на построение кластерных ВС. Например, Томас Стерлинг оценивает приемлемый уровень расходов на КС кластерной системы как 25–30% всех расходов на аппаратуру кластерной ВС [27].
Такой подход в нашем проекте стал возможен благодаря существенным сдвигам в развитии архитектуры и структуры сетевых средств, методов их взаимодействия с ЭВМ, которые стали реальностью со времени создания нашей параллельной ВС на "Электронике 81Б". Выросли технико-экономические характеристики средств локальных сетей массового применения. Сетевые контроллеры Fast Ethernet для шины PCI стали массовой продукцией по цене 15–35 долл., стоимость сетевых контроллеров Gigabit Ethernet с тысяч долларов уменьшилась до сотен долларов.
В сетевых средствах массового производства произошел переход от моноканальных архитектур, с использованием физической или логической шины (концентраторы) к архитектурам с коммутацией кадров. Замена моноканала на коммутатор с масштабируемой структурой позволяет варьировать пропускную способность КС с ростом числа абонентов – ВМ, иметь низкие значения задержек передачи сообщений L и сохранять их при росте числа ВМ в кластерной ВС.
Кроме того, построенная на коммутаторах структура ЛВС (а в кластерной ВС – ее КС) переводит все связи между узлами физической структуры параллельной ВС в категорию каналов "точка – точка" как на физическом, так и на канальном уровне. Это позволило во многих серийно выпускаемых сетевых блоках перейти на дуплексный режим работы канала подключения КК в ВМ к сетевой инфраструктуре, что дает почти двойное увеличение пропускной способности стыка ВМ с КС.
Ранее в нашем проекте параллельной ВС на "Электронике 81Б" были реализованы все эти возможности, только на базе коммуникационных средств специальной разработки. Теперь же можно использовать серийные, существенно более дешевые блоки. Конечно, пока не все из тех средств архитектурной поддержки, которые нужны для параллельных ВС, мы можем найти в сетевых средствах современных локальных сетей. Однако потери от их программной эмуляции – это плата за дешевизну серийных средств и таким образом всей кластерной ВС в целом.
Другая оборотная сторона применения серийных средств локальных сетей для КС – ограниченная масштабируемость кластерных ВС на серийных технических средствах (в данном контексте – сетевых средств). Для малых конфигураций кластерных ВС (например, с одним коммутатором средней стоимости) удельная пропускная способность КС на одного абонента, показатели L, o, g, будут определяться тем, что позволяют получить используемые технические средства ВМ, узла параллельной кластерной ВС – сетевого контроллера, системного блока. Наращивание конфигурации в пределах, определяемых заложенными в серийный коммутатор возможностями наращивания (stackable switches) и комплексирования с другими коммутаторами по каналам повышенной пропускной способности (например, каналов Gigabit Ethernet для коммутаторов FastEthernet), позволяет не ухудшать эти показатели при масштабировании системы. Так, удельные показатели КС 36-процессорной конфигурации кластерной ВС (рис. 10) будут практически такими же, как и для 8-процессорной конфигурации (рис. 8).
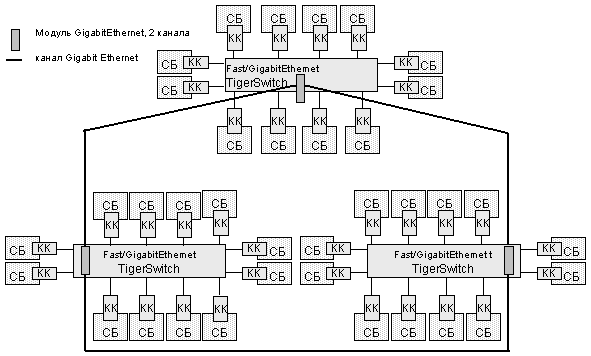
36-процессорная кластерная ВС
Конечно, можно поставить и тысячу, и десять тысяч системных блоков ПЭВМ и соединить их некоторой структурой КС с сетью из коммутаторов и кабелей между ними. В мире известны десятки кластерных ВС с числом процессоров больше тысячи. Однако для каждого из имеющегося на рынке набора серийных сетевых блоков будут свои ограничения на возможность масштабирования структуры сети с сохранением удельной пропускной способности на один абонент КС. Дальнейшее увеличение числа абонентов сети ведет к уменьшению пропускной способности КС в расчете на одного абонента, к росту показателей L, o, g, критичных для функционирования параллельной ВС. И такая кластерная ВС будет работоспособна, и она сможет решать задачи. Однако все на большем числе задач будут расти потери ресурса процессорного времени и падать эффективная производительность. Эти факторы и приводят к тому, что эффективная производительность кластерных ВС (real applications performance – RAP) оценивается как 5–15% от их пиковой производительности (Peak Advertised Performance, PAP) [28]. Для сравнения: у лучше сбалансированных профессиональных высокопроизводительных ВК – малопроцессорных ВК из векторных процессоров – это соотношение оценивается как 30–50%.
Наконец, большое значение имеет появление поддержки архитектуры виртуального интерфейса (Virtual Interface Architecture, VIA) в архитектуре коммуникационных контроллеров и сопровождающих их драйверах для серийных ОС (в нашем случае – для ОС Linux). Один из авторов настоящей статьи, Шейнин Ю. Е., был участником (contributing member) международной рабочей группы, разрабатывавшей и исследовавшей спецификацию VIA. Качественно новый уровень организации взаимодействия ПО, выполняющегося на центральном процессоре ВМ, с коммуникационным контроллером позволяет существенно снизить накладные расходы o и задержки передачи сообщений L. Так, накладные расходы o удается сократить до 4 мкс [29]. В нашей кластерной ВС мы используем сетевые контроллеры типа Intel Pro 100 с драйверами M-VIA для ОС Linux.
Еще лучшие характеристики можно получать при использовании коммуникационной среды, построенной по технологии АТМ [30]. Для этой технологии также серийно выпускаются и КК, и коммутаторы. Однако современный рынок СВТ сложился таким образом, что сетевые средства по технологии АТМ не получили столь массового распространения, как современные технологии Ethernet. В результате сетевые узлы и блоки не стали столь массовой продукцией и цены на них существенно, в несколько раз выше.
Перспективы развития вычислительных систем
Высокопроизводительные вычислительные средства давно стали ключевым аспектом развития науки и техники. Компьютерное моделирование широко используется в естественных науках для исследования явлений и процессов реального мира, в прикладных дисциплинах – для анализа и оптимизации инженерных решений. Прогнозируется дальнейший рост значимости компьютерного моделирования вычислительных экспериментов для развития фундаментальных и прикладных наук, прогресса в инженерных дисциплинах разного профиля, перехода от натурных экспериментов к исследованиям на компьютерных моделях. Яркий пример – замена ядерных взрывов на компьютерное моделирование и вычислительные эксперименты. Это требует разработки самых передовых методов компьютерного моделирования и суперкомпьютерных вычислительных средств, на что направлена, например, целевая научно-техническая программа министерства энергетики США DOE/ASCI Program (Department of Energy, DOE; Accelerated Strategic Computing Initiative, ASCI) [32].
Представление о широте спектра задач для массово-параллельных систем и типовых классов вычислительных алгоритмов дает их сводка на рис. 11 [33]. Очевидно, что это сегодняшнее представление является лишь малой частью тех задач, которые придется решать массово-параллельным системам в ближайшее десятилетие.
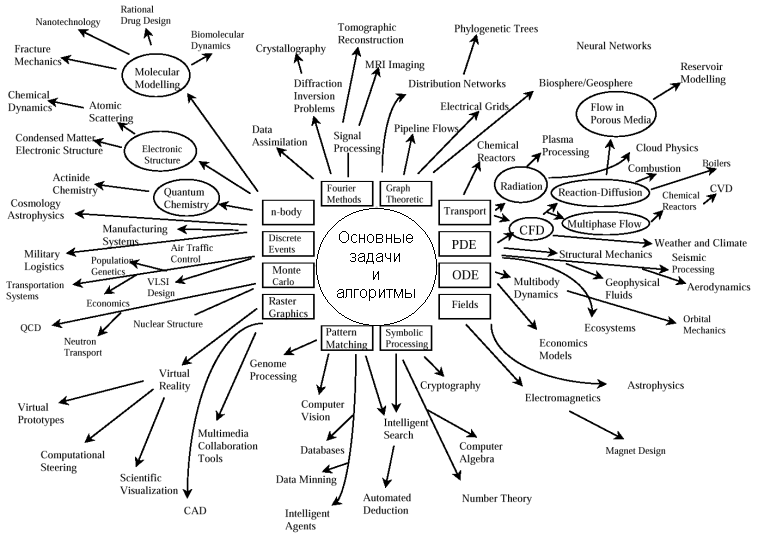
Перспективные задачи для массово-параллельных ВС
Сформировались и получили признание дисциплины, базирующиеся на высокопроизводительной компьютерной обработке и моделировании: вычислительная метеорология (моделирование погодных и климатических процессов), астрономия и астрофизика (исследование звезд, суперновых, нейтронных звезд, космология), вычислительная физика, вычислительная химия (Computational Chemistry), молекулярное моделирование (Molecular Modelling) и др. Они играют все более значимую роль в развитии современных научных знаний. Например, Нобелевскую премию в области химии в 1998 г. получил профессор Walter Kohn за создание теории Density Functional Theory, составляющей теоретическую основу многих вычислительных экспериментов на суперкомпьютерах в области вычислительной химии [34].
Наряду с ними развиваются новые научные дисциплины, новые отрасли знаний [33]: вычислительная экономика (Computational Economics), вычислительная логика (Computational Logic), вычислительная экология (Computational Ecology), биоинформатика (Bioinformatics), вычислительная лингвистика (Computational Linguistics), вычислительная электроника (Computational Electronics) и др.
Не меньшее значение придается расширению применения методов и технологий суперкомпьютерной обработки данных в новых сферах, за рамками традиционно научных и инженерных областей, для улучшения сервисов для широких слоев населения и накопления знаний человеческим обществом. Базирующиеся на суперкомпьютерных возможностях обработки информации "интеллектуальные" экспертные системы смогут оперативно вырабатывать оптимальные решения в различных областях – от здравоохранения до прогноза поведения рынков. Перспективная задача – извлечение и накопление знаний на основе сложных алгоритмов извлечения данных из огромных накопленных баз данных (data mining). Пример нового направления – Web-mining, извлечение знаний из информации, хранящейся в Интернете на веб-серверах – самом большом и постоянно расширяющемся источнике информации в современном мире. Задача является еще более сложной, чем data mining (в силу отсутствия единообразного структурированности информации), требующая для своего решения интеграции методов data mining, компьютерной лингвистики, понимания образов, социальных наук, помноженного на огромные вычислительные мощности перспективных массово-параллельных компьютеров. Получаемые в результате знания могут стать основной развития новых направлений в социальных и гуманитарных исследованиях.
Растет значение высокопроизводительных вычислительных средств в задачах непосредственного управления оборудованием и системами, которые имеют критический характер для нормального функционирования и самого существования человеческого общества.
Массово-параллельные вычисления с терафлоповой и петафлоповой (1015) производительностью необходимы и в сложных приборных комплексах. Источники рентгеновского излучения в исследовательских центрах, гигагерцовые NMR-системы, ускорители элементарных частиц, аэродинамические трубы и другие научные приборные комплексы генерируют огромные потоки данных, сотни мегабайт в секунду и более [35, 36]. Все эти данные требуют сложной обработки и комплексного анализа [37, 38]. Дальнейшее развитие и методик экспериментальных научных исследований, и научных приборных комплексов требует анализа поступающих с приборов потоков данных в реальном времени так, чтобы по их результатам учеными мог контролироваться, модифицироваться и управляться ход самого научного эксперимента.
Еще более захватывающая научная проблема, обещающая качественно-новые возможности научных исследований, – непосредственная интеграция приборных комплексов для проведения экспериментов и массово-параллельных суперкомпьютерных вычислительных средств, ведущих в реальном времени моделирование лежащих в основе проводимого эксперимента физических, химических и т. п. процессов. При этом появляется возможность прямого взаимодействия эксперимента, теории и научных представлений исследователей (scientific insight), их взаимовлияния в единой интерактивной среде научных исследований.
Перспективные задачи характеризуются большими размерностями обрабатываемых массивов данных, большими объемами вычислений, требуют огромных вычислительных ресурсов [39]. Среди перечисленных выше типовых задач многие относятся к задачам большой вычислительной интенсивности (computation intensive), объем вычислений которых растет значительно быстрее роста размерности задачи и быстрее роста объема обрабатываемых данных. Например, даже для традиционной задачи умножения матриц многие известные алгоритмы параллельного умножения матриц требуют O(N3) операций вычислений и O(N2) пересылок данных [40]. Для широкого класса задач трехмерного моделирования физических систем отмечен рост вычислительной сложности (объема вычислений) как n4, при росте объема требуемой памяти как n3. В вычислительной химии имеется большое число задач, вычислительная сложность которых характеризуется как n5, n7, n! и др.
В этих условиях достигнутый терафлоповый (1012 операций с плавающей запятой в секунду) уровень производительности суперкомпьютерных систем является недостаточным. Уже сегодня есть реальные, актуальные и готовые к решению задачи, требующие производительности в десятки и сотни терафлоп, ясны постановки ряда задач, требующие производительности в 1000 терафлоп. На повестке дня – создание в ближайшее десятилетие вычислительных систем с производительностью, измеряемой в петафлопах – 1015 операций в секунду, которые уже называют петафлоповыми компьютерами (Petaflop Computers). По оценкам PITAC (Консультативного совета по информационным технологиям при президенте США) задача создания петафлоповых суперкомпьютеров должна быть решена к 2007 г. [41].
Вычислительные машины предназначены для решения задач.
Общая схема решения задач имеет вид Ячел -> Яос ->Япр ->Ямаш -> Ярез, где Ячел – формулировка задачи на естественном языке, Яос – формулировка задачи на языке основных соотношений, Япр – формулировка задачи на языке программирования, Ямаш – формулировка задачи на машинном языке, Ярез – формулировка задачи на языке результата в виде графиков, таблиц, изображений, текстов, звуков и т. п.
К сожалению, для большинства задач имеется только формулировка на естественном языке, множество задач плохо формализованы. Поэтому актуальным является переход от описания на естественном языке к описанию на языке основных соотношений; лингвокомбинаторное моделирование является одним из способов такой формализации [22]. В результате такой формализации порождаются рекурсивные структуры со структурированной неопределенностью. Таким образом, рекурсивная структура машин должна включать три составляющих – явления, смыслы и структурированную неопределенность, которые наличествуют в любой задаче.
Литература
- А. А. Воронов, А. Р. Гарбузов, Б. Л. Ермилов, М. Б. Игнатьев, Г. Н. Соколов, Ян Си Зен. Цифровые аналоги для систем автоматического управления. Изд. АН СССР, 1960.
- М. Б. Игнатьев. Голономные автоматические системы. Л.–М., Изд. АН СССР, 1963.
- А. И. Мальцев. Алгоритмы и рекурсивные функции. М., 1965.
- М. Б. Игнатьев. О совместном использовании принципов введения избыточности и обратной связи для построения ультраустойчивых систем. Труды Ш Всесоюзного совещания по автоматическому управлению, т. 1. Изд. АН СССР, 1968.
- М. Б. Игнатьев. Метод избыточных переменных для функционального кодирования цифровых автоматов. Сб. "Теория автоматов", №4. Киев, ИК АН УССР, 1969.
- М. Б. Игнатьев. О лингвистическом подходе к анализу и синтезу сложных систем. Тезисы Межвузовской научно-технической конференции "Техническая кибернетика". Изд. МВТУ, 1969.
- М. Б. Игнатьев. Избыточность в многоцелевых системах. Труды IV симпозиума по проблеме избыточности. Л., 1970.
- М. Б. Игнатьев, Ф. М. Кулаков, А. М. Покровский. Алгоритмы управления роботами-манипуляторами. М., Машиностроение, 1972. США, Вирджиния пресс, 1973.
- Г. С. Бритов, М. Б. Игнатьев, Л. А. Мироновский, Ю. М. Смирнов. Управление вычислительными процессами. ЛГУ, 1973.
- V. Glushkov, M. Ignatyev, V. Miasnikov, V. Torgashev. Recursive machines and computing technology. Proceedings IFIP-74, computer hardware and architecture, p. 65–70, Stockholm, August 5–10, 1974.
- М. Б. Игнатьев, В. А. Мясников, А. М. Покровский. Программное управление оборудованием. Изд. 2-е. М., Машиностроение, 1984.
- М. Б. Игнатьев, В. А. Мясников, В. А. Торгашев. Рекурсивные вычислительные машины. Препринт №12. ИТМ и ВТ АН СССР, 1977.
- М. Б. Игнатьев, В. М. Кисельников, В. А. Торгашев, В. Б. Смирнов. Ассоциативное запоминающее устройство. А. с. 4844562. Опубл. в Б. И., №34, 1975.
- А. А. Бекасова, С. В. Горбачев, М. Б. Игнатьев, В. А. Мясников, В. А. Торгашев. Процессор с микропрограммным управлением. А. с. 814118 с приоритетом от 18.10.1979.
- С. В. Горбачев, М. Б. Игнатьев, В. М. Кисельников, В. А. Мясников, В. А. Торгашев. Многопроцессорная вычислительная система. А. с. 962965 с приоритетом от 27 августа 1974. Опубл. в Б. И., №36, 1982.
- М. Б. Игнатьев, В. А. Мясников, В. В. Фильчаков. Организация вычислительного процесса при решении прикладных задач на многопроцессорной системе с рекурсивной организацией. Журнал АН УССР, сер. Кибернетика, 1984, №3, с. 30–37.
- Рекурсия. Ст. в Математической энциклопедии, т. 4. М, 1984, с. 962–966.
- В. А. Мясников, М. Б. Игнатьев, А. А. Кочкин, Ю. Е. Шейнин. Микропроцессоры – системы программирования и отладки. М., Энергоатомиздат, 1985.
- С. В. Горбачев, М. Б. Игнатьев, Ю. Е. Шейнин. Рекурсивные ЭВМ массового применения. Тезисы 11-й Всесоюзной конференции по актуальным проблемам информатики и вычислительной техники. Ереван, АН Армянской ССР, 1987.
- М. Б. Игнатьев, Я. Комора. Обобщенная параметрическая модель реализации локально-рекурсивных структур в трехмерных интегральных схемах. ДАН СССР, 1991, т. 320, №5, с. 1058–1062.
- М. Б. Игнатьев, В. В. Фильчаков, Л. Г. Осовецкий. Активные методы обеспечения надежности алгоритмов и программ. Политехника, 1992.
- М. Б. Игнатьев. Лингвокомбинаторное моделирование плохо формализованных систем. Информационно-управляющие системы, 2003, №6, с. 34–37.
- С. А. Яновская. Методологические проблемы науки. М, 1972.
- П. Г. Суворова. Диалектика абстрактного и конкретного в понятии "архитектура ЭВМ". Сб. "Новые идеи в философии науки и научном познании". Под ред. Ю. И. Мирошникова. Екатеринбург, 2002.
- Т. Е. Аладова, М. Б. Игнатьев, Ю. Е. Шейнин. Распределенный монитор для отладки программного обеспечения мультипроцессорных систем. Микропроцессорные средства и системы, 1990, №5, с. 49–56.
- High Performance Cluster Computing: Architectures and Systems. Rajkumar Buyya (editor), ISBN 0–13–013784–7, Prentice Hall PTR, NJ, USA, 1999, v.1, 2.
- Th. Sterling. The Future of Cluster Interconnects: Infiniband or Ethernet. A Beowulf Perspective. Panel Presentation at IEEE Cluster 2000 Conference.
- G. Bell, J. Gray. High Performance Computing: Crays, Clusters, and Centers. What Next? Microsoft Research, Technical Report MSR-TR-2001–76, 2001. 7 p.
- Ph. Buonadonna, A. Geweke, D. Culler. An Implementation and Analysis of the Virtual Interface Architecture. Proceedings of SC98, Orlando, Florida, November 1998. 9 p.
- S. Gorbachev, E. Gontcharova, M. Ignatiev, Y. E. Sheynin. Distributed High Performance Computing Over ATM Networks. In: Proceedings of the High Performance Computing (HPC ’98), ASTC’98 Conference, Boston, USA, April 1998, p. 216–221.
- М. Б. Игнатьев, Ю. Е. Шейнин. 25 лет со времени создания рекурсивной вычислительной машины высокой производительности и надежности и проблемы параллельных вычислений. Доклад на пленарном заседании 23-й международной конференции по школьной информатике и проблемам устойчивого развития, Санкт-Петербург, 16 апреля 2004 г.
- G. G. Weigand. Petaflop II. The ASCI Challenge. Petaflops II. 2nd Conference on Enabling Technologies for Peta(fl)ops Computing. Santa Barbara, California, USA, February 1999.
- R. Stevens. Applications for PetaFLOPS. Petaflops II. 2nd Conference on Enabling Technologies for Peta(fl)ops Computing. Santa Barbara, California, USA, February 1999.
- J. Bashor. Researchers Achieve One Teraflop Performance With Supercomputer Simulation Of Magnetism. Berkeley Research News, 1998, November 9.
- W. E. Johnston. Real-Time Widely Distributed Instrumentation Systems. The Grid: Blueprint for a New Computing Infrastructure. Ed. by Ian Foster and Carl Kesselman. Morgan Kaufmann. Pubs. August 1998.
- W. E. Johnston e. a. High-Speed Distributed Data Handling for On-Line Instrumentation Systems. Proceedings of ACM/IEEE SC97: High Performance Networking and Computing. Nov., 1997.
- William E. Johnston e. a. High-Speed Distributed Data Handling for High-Energy and Nuclear Physics. Invited lecture (W. Johnston) at the 1997 CERN School of Computing, Pruhonice (Prague), Czech Republic. 17–30 August 1997. Published in the "Proceedings of the 1997 CERN School of Computing." Also published in the proceedings of Computing in High Energy Physics, Berlin, Germany. April, 1997.
- W. Johnston e. a. Real-Time Generation and Cataloguing of Large Data-Objects in Widely Distributed Environments. International Journal of Digital Libraries May, 1998.
- D. H. Bailey. Petaflops Algorithms. Petaflops II. 2nd Conference on Enabling Technologies for Peta(fl)ops Computing. Santa Barbara, California, USA, February 1999.
- J. Choi. A New Parallel Matrix Multiplication Algorithm on Distributed-Memory Concurrent Computers. Center for Research on Parallel Computation, Rice University, September 1997, CRPC-TR97758, 19 р.
- Information Technology Research: Investing in Our Future. PITAC – Report to the President, February 24, 1999.
Статья опубликована 08.12.2005 г.